The problem
Finding information inside your own documents should be instant
Professional services practitioners at large law firms, accounting firms, and private equity houses spend a significant part of their day doing something that should be instant: finding information inside their own documents.
They open files one by one. They scan page by page. They search by filename when they can remember it. When they need to know what happened on a similar deal two years ago, they either know who to ask, or they don't find out at all.
The product team had an answer: an AI assistant that could sit inside the document management workspace, understand what engagement the user was in, and respond to plain-language questions about the documents and institutional knowledge available to them.
The problem I was brought in to solve was not whether this was a good idea. It clearly was. The problem was: what does this actually look like, and how does it work?
The AI was built by a separate internal team on a separate platform. It was being embedded into a document management product with its own navigation model, its own user base, and its own established interaction patterns. My job was to design the integration: to define how users would encounter the AI, how it would understand where they were, what they could ask it about, and how they would trust what it told them. This had not been done before inside the company. There was no template.
My role & constraints
Owning the design end to end, without PM coverage
I owned the design end to end on the document management platform side. That meant running the discovery and requirements phase, defining experience requirements and design principles, producing concept exploration screens and a feasibility prototype, maintaining a living design specification, presenting directly to senior directors, and translating decisions into structured engineering requirements.
The constraint I did not expect was the PM gap. Three product managers were absent simultaneously — one departed in May 2026, one in June 2026, and a third was on paternity leave. I was moving work forward without active PM coverage for most of the project. This shaped how I worked: I had to be more assertive than usual about scoping and about who had authority to sign off on what. I was careful not to resolve product-level questions through design decisions, and I flagged the gap formally rather than quietly filling it.
I also had to navigate an undefined design ownership boundary. The AI product team had their own designer assigned to the embedded integration, and our respective scopes had not been formally agreed when I started. I worked transparently alongside their team, shared work regularly, and pushed for the boundary to be defined.
Discovery
What I knew and what I did not
What I had
The project started with a two-day offsite in April 2026 where platform and AI product leadership worked through the integration architecture together. I synthesised the output into a UX brief and an IA diagram. This gave me a starting point for what was in scope, but most of the decisions from the offsite were directional, not final.
Over April and May I gathered:
- A capability description document detailing what the AI product could actually do.
- Multiple stakeholder sessions with the Senior Director of Product Management, the Lead Product Designer covering document intelligence, and the principal PM managing AI feasibility questions.
- Competitive context: how Microsoft Copilot, Harvey, and general-purpose AI tools were behaving in the same space, and where they were failing users.
- Screenshots and flows from the legacy AI feature being replaced, as a baseline for what users already had.
What I did not have
No direct user research with practitioners was available at this stage. The firm's enterprise clients were not accessible for testing. I was working from third-hand feedback, observed user behaviour described by product leadership, and reasonable inference from the domain. I documented this clearly rather than treating internal alignment as validated user insight.
Every assumption in the design spec is labelled as a hypothesis until usage data proves otherwise.
The design challenge
How the AI knows what to search across — and who controls it
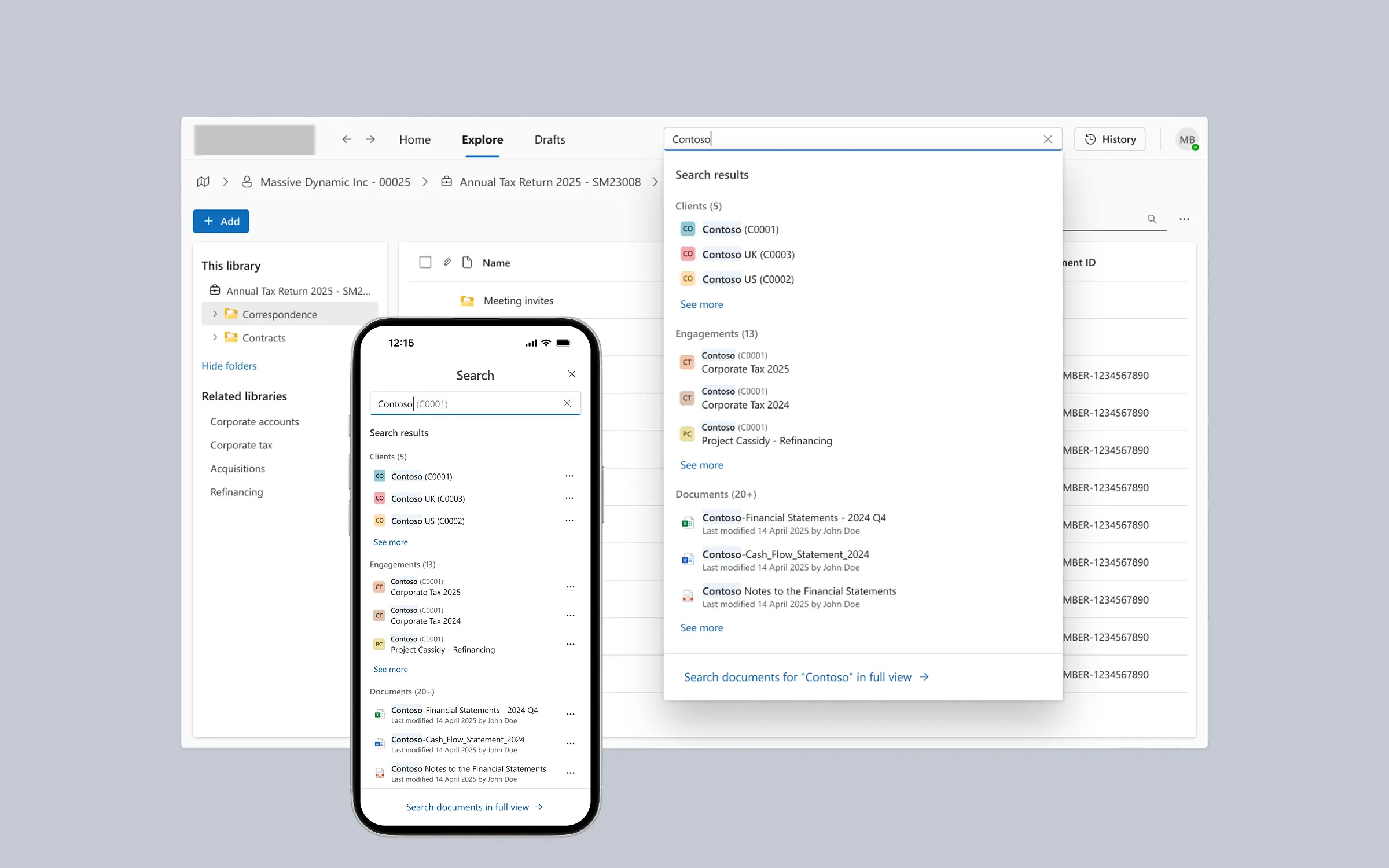
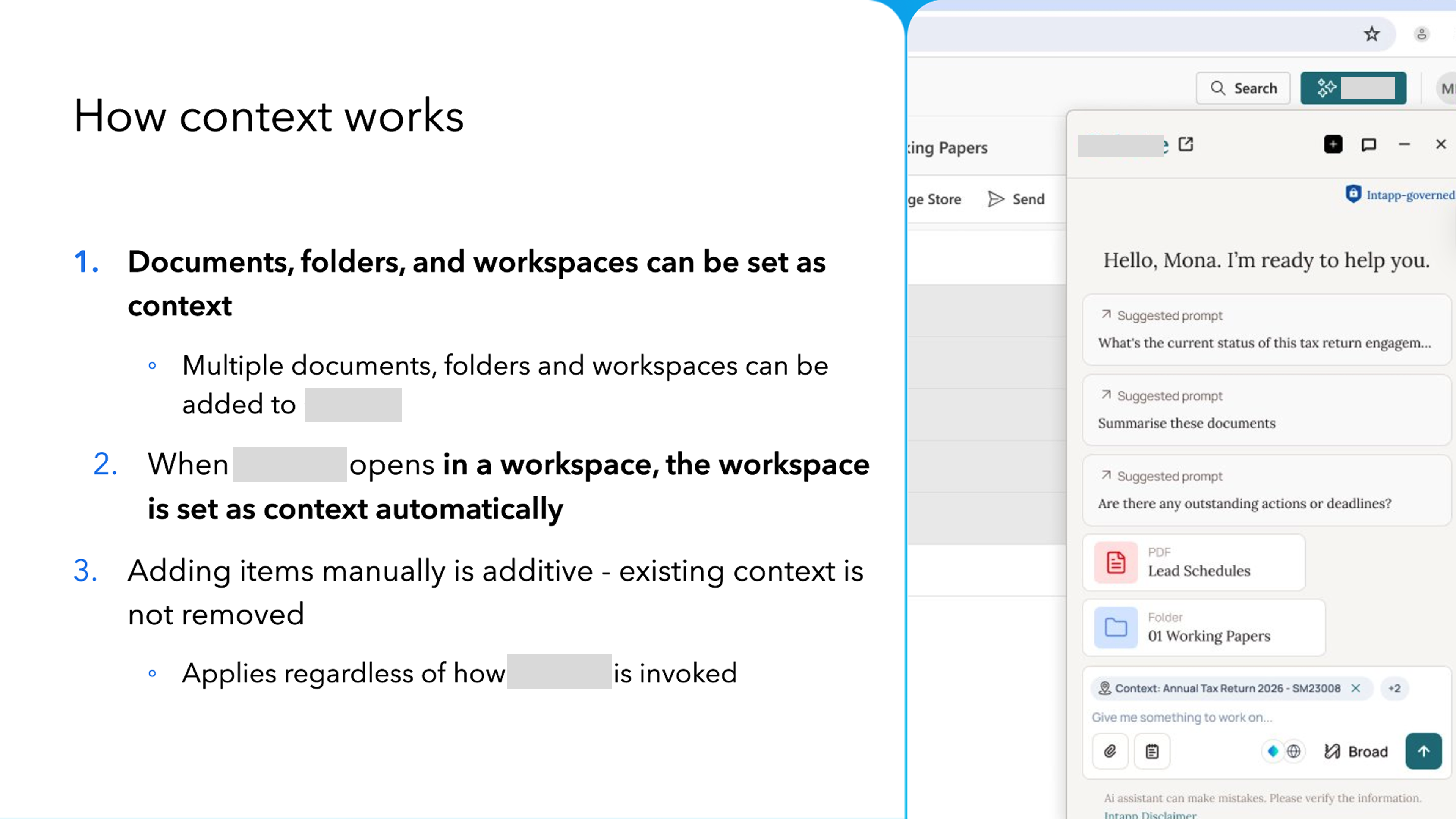
The central design question was about context — specifically, how the AI knows what to search across and how the user controls that. A user inside an engagement workspace should not have to tell the AI which engagement they are in. But what happens when they add a specific document? Does it replace the workspace context, or add to it? What about when they right-click a document and invoke the AI directly, from a closed state?
These are not interface questions. They are mental model questions. And they had real engineering dependencies — because the AI platform did not distinguish between how it was invoked. Whether different entry points could produce different behaviour depended on whether a technical signal was available.
My approach was to resist the pressure to pick one answer early. I defined two distinct scenarios — the AI already open (Scenario A) and the AI invoked from closed on a specific item (Scenario B) — and held them separately. Scenario A was confirmed as additive: adding content never removes existing context. Scenario B remained an open decision, explicitly tracked in the specification, pending feasibility input.
This mattered because product leadership's position changed between two sessions within four days. In the first, the direction was that explicit invocation should scope tightly to the selected item; in the second, it shifted toward everything being additive. I did not resolve this by accepting the most recent answer. I went back to the transcript, identified that the second position was reached in a discussion specifically about drag and drop — not explicit invocation — and that the speaker had acknowledged uncertainty. I documented both positions, separated the scenarios, and held the decision open rather than presenting a false closure to engineering.
Process
From feasibility to engineering-ready scope
Phase 1: feasibility prototype (May 2026)
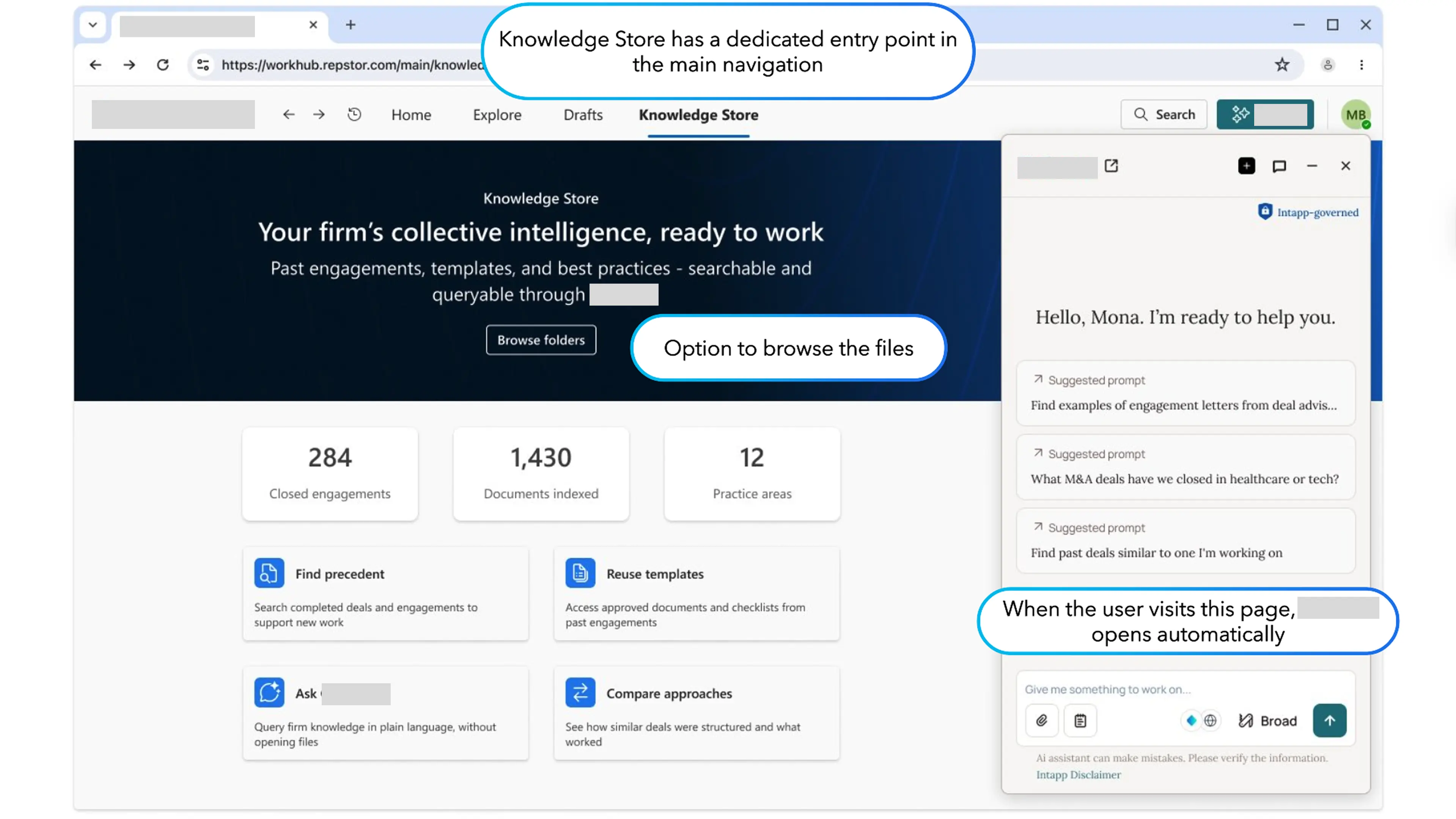
Before committing to detailed requirements, I produced a feasibility prototype to test whether the integration concepts were viable. It covered three scenarios: workspace context, document interrogation, and Knowledge Store connector. This was not a polished prototype — it was a thinking tool and a conversation starter with the AI platform team and product leadership.
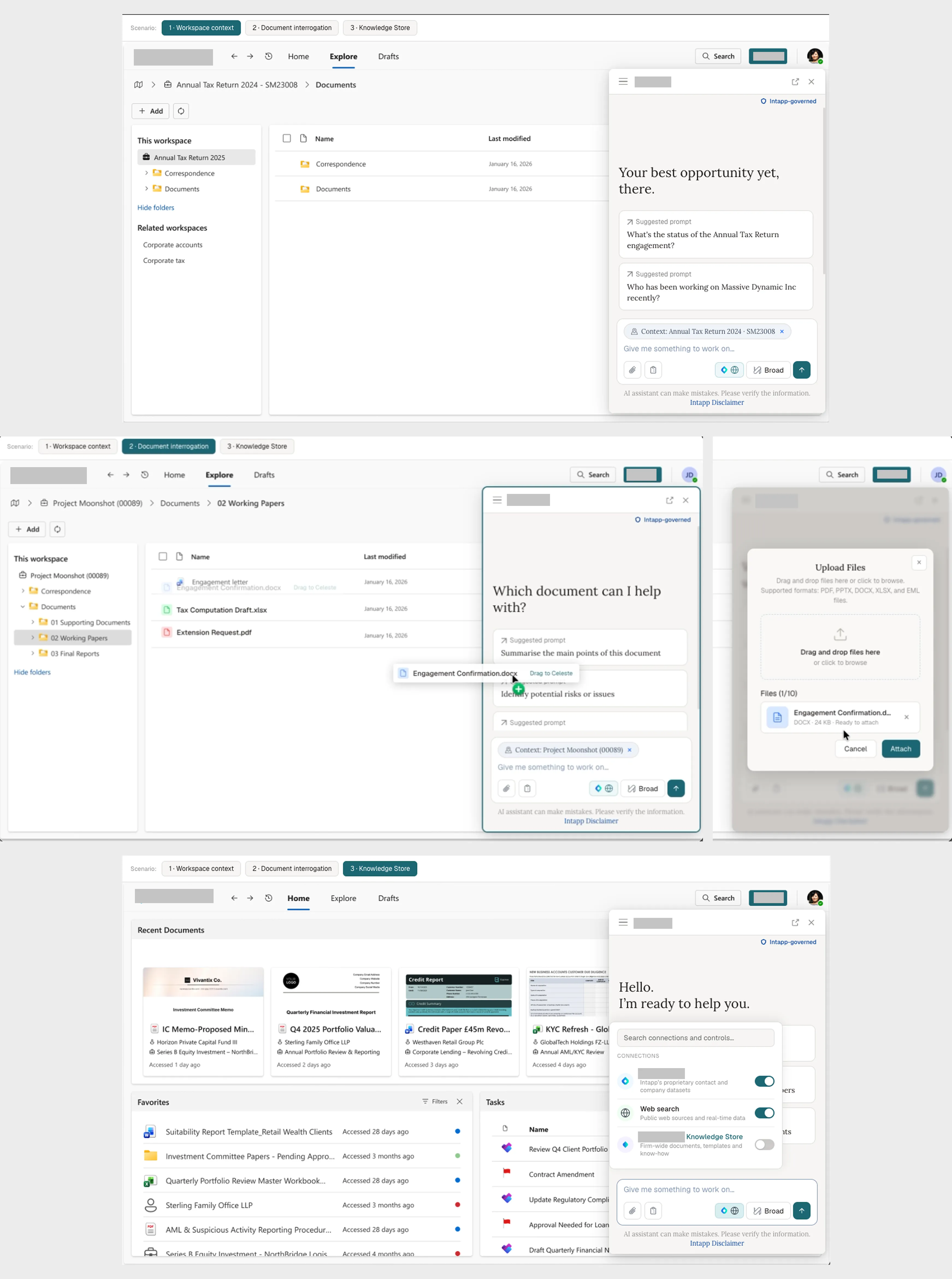
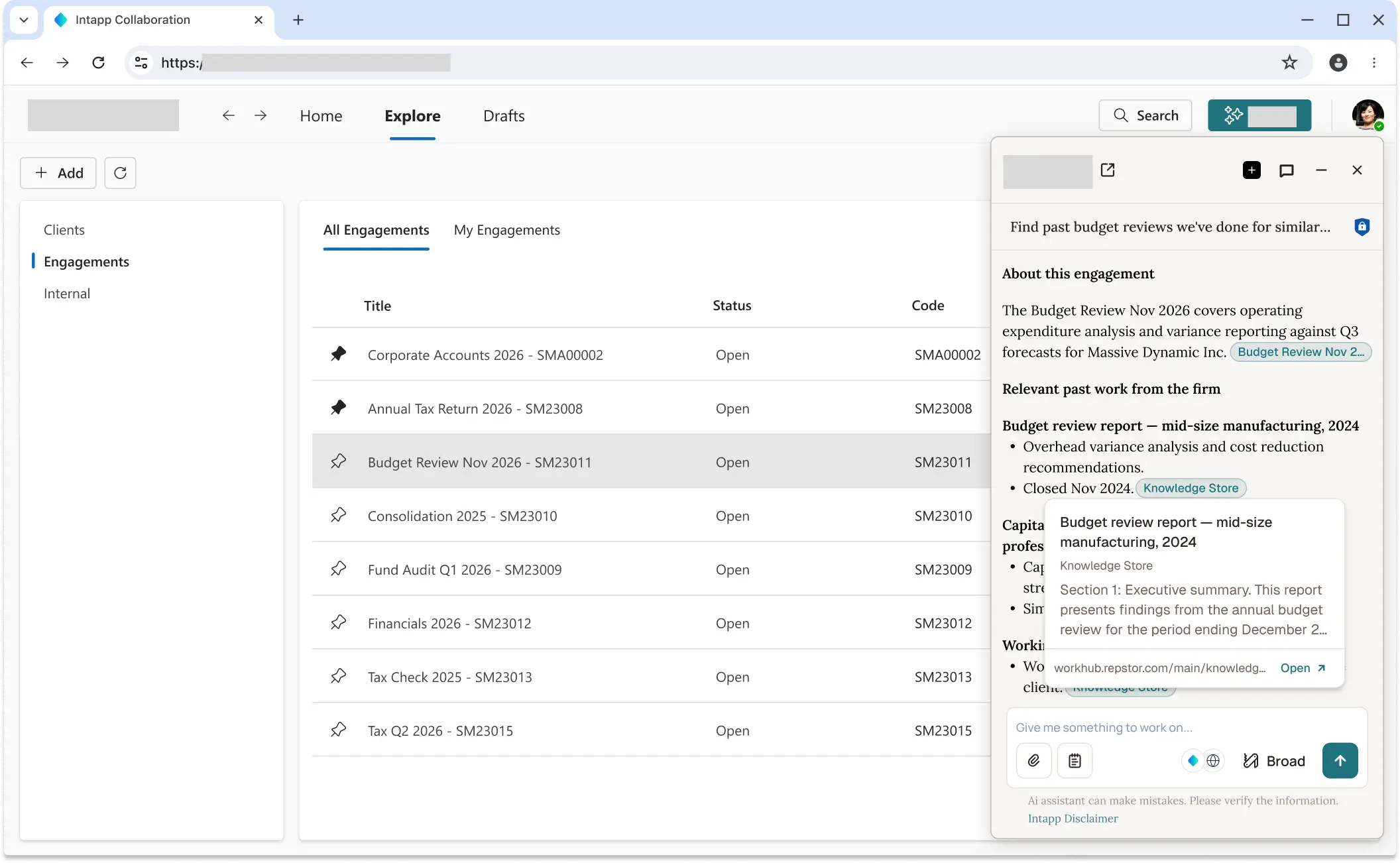
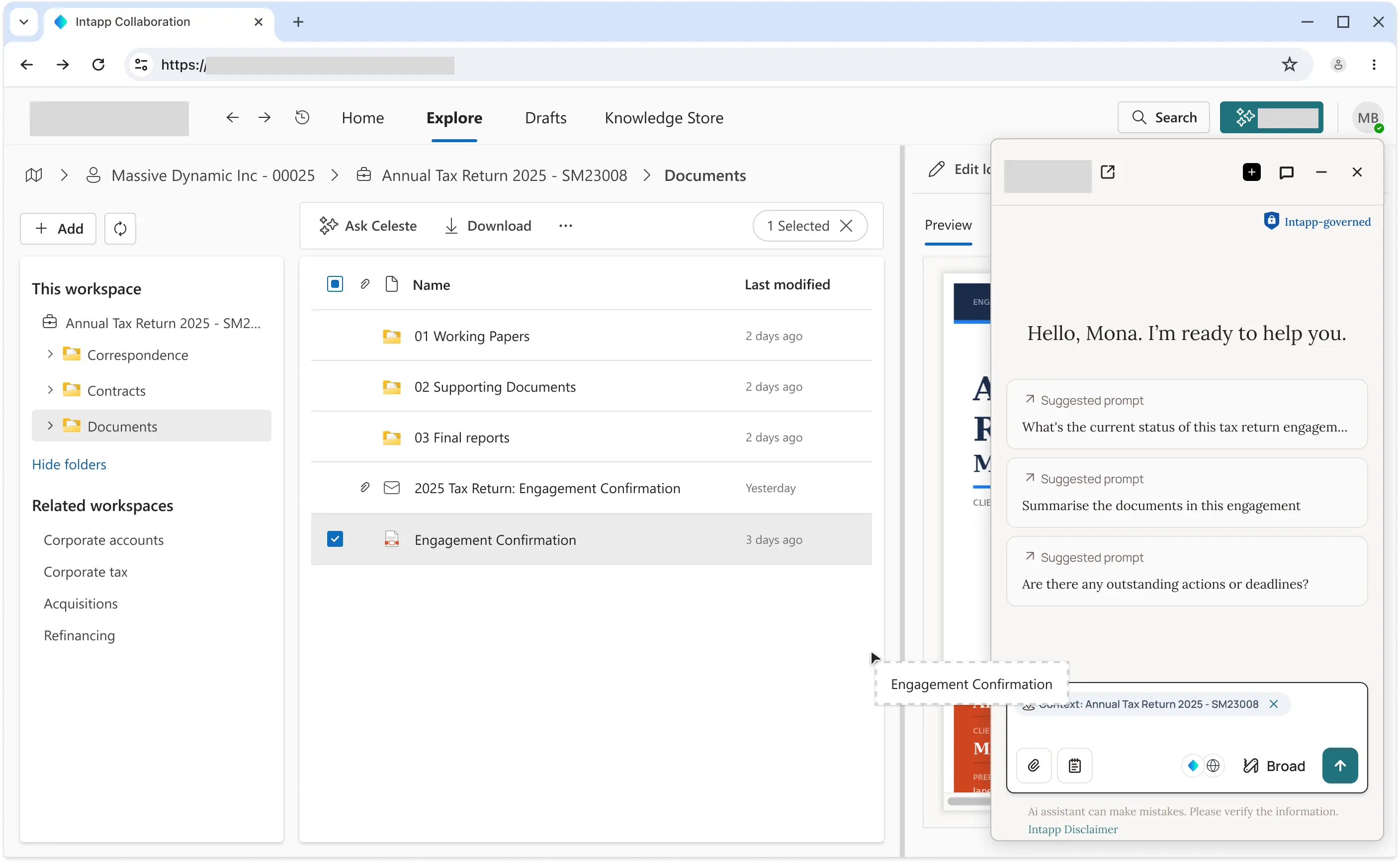
Phase 2: requirements and alignment (May–June 2026)
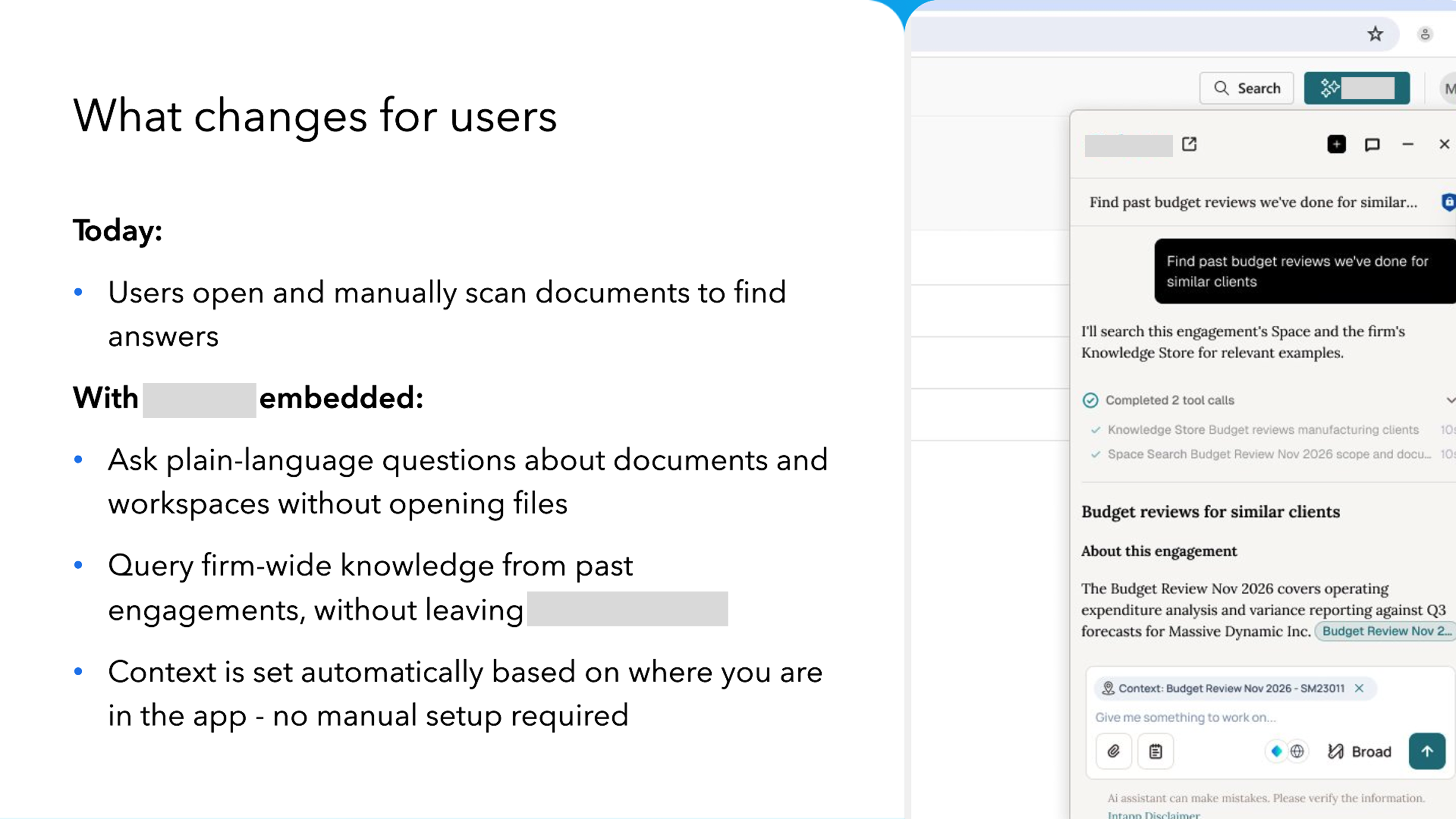
After the feasibility direction was agreed, I produced a detailed requirements presentation covering context-setting, Knowledge Store access, chat experience, and UI appearance. This went through two rounds of review, then a shorter version for senior leadership sign-off. Everything was tracked in a living design specification — the single source of truth, not the deck or meeting notes.
Phase 3: engineering requirements (June 2026)
Once leadership alignment was reached, I translated the design specification into a structured engineering requirements document: 13 user stories with full acceptance criteria, a release scope split (August 2026 for the like-for-like replacement, November 2026 for new capability), and a clearly annotated section distinguishing confirmed scope from items still under discussion. The scope split was itself a significant output — it took careful argument to establish that shipping everything in August would produce a worse product than shipping a clean replacement first and building on it properly in November. That argument landed.
Key design decisions
The principles that shaped the integration
Navigation as the context mechanism
Context does not change when the user adds content. It changes when they navigate. Closing the panel on navigation and rescoping on reopen means the system always reflects where the user is, without requiring any active management. This protects users who work across multiple engagements simultaneously from accidentally querying the wrong workspace.
Additive context, never silent replacement
Any content a user adds to an active conversation is additive. The existing context is never removed without a deliberate user action. If you have been building context across a session, the system should not silently undo it.
Source attribution as a design principle, not a feature
Every AI response must identify where the answer came from: a live working document, the firm-wide Knowledge Store, or both.
I defined source attribution as a non-negotiable design principle, not a nice-to-have — because the product's value depends on users trusting the answer, and trust requires transparency about source.
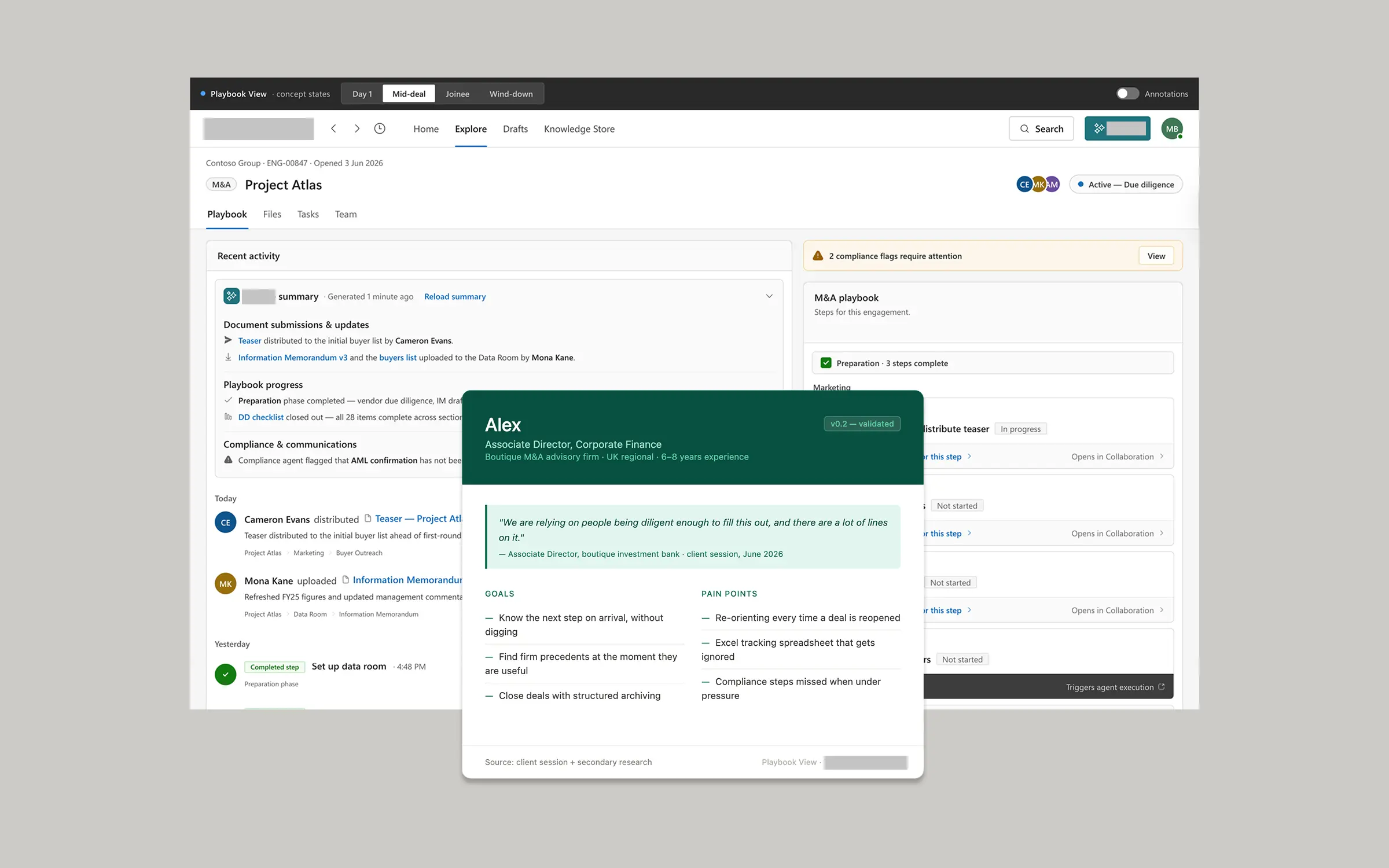
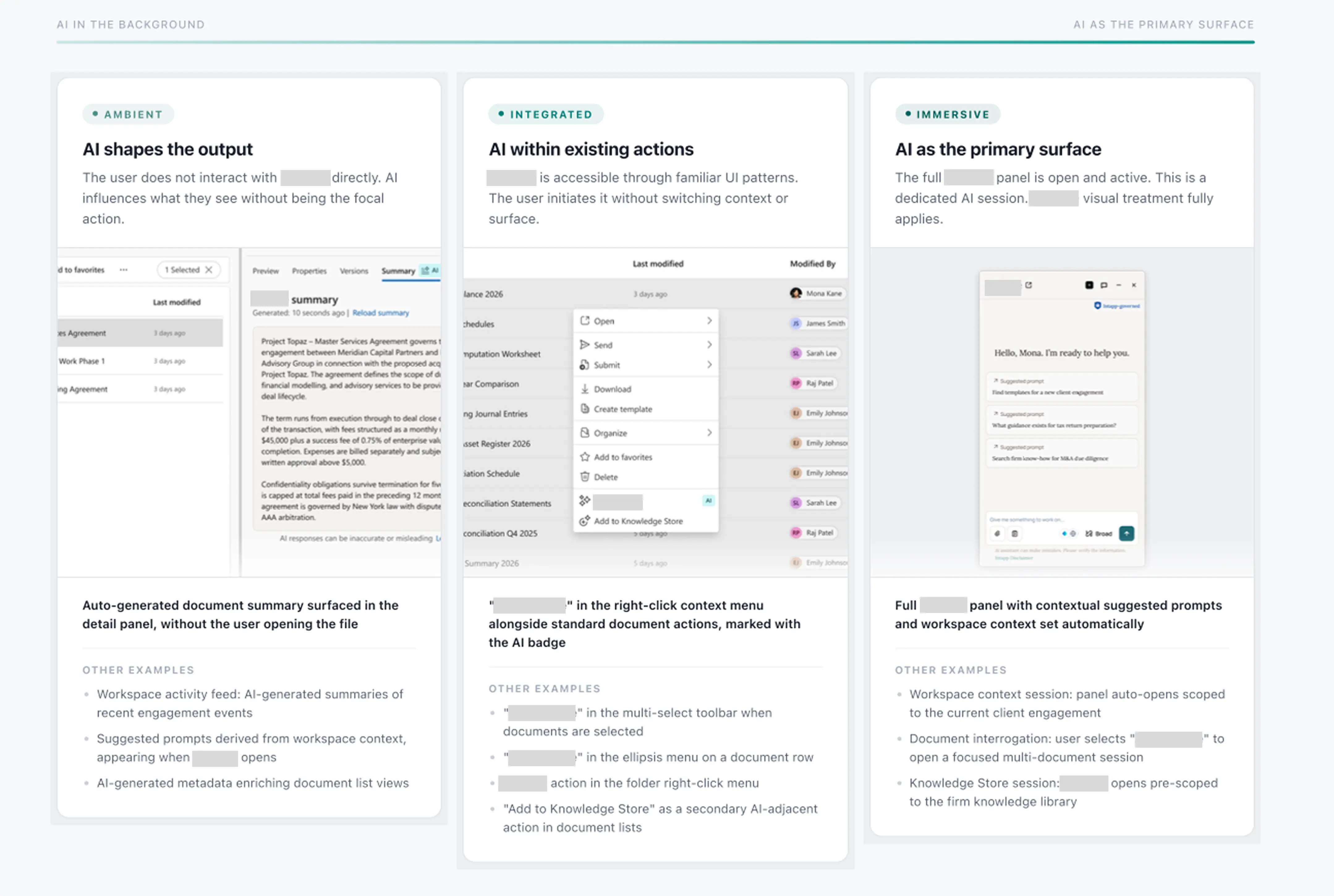
Three levels of AI presence
I mapped the AI assistant's presence across three levels: Immersive (the full AI panel), Integrated (AI built into existing actions such as right-click menus), and Ambient (AI influencing output without being the focal action, such as auto-generated document summaries). This kept AI visible where users needed to know it was acting, and invisible where it was just helping.
Artifacts produced
What was delivered
- UX brief synthesising offsite output.
- IA diagram.
- Feasibility prototype: three scenarios (workspace context, document interrogation, Knowledge Store).
- Concept exploration screens: context-switching, document entry points, drag and drop, folder context, Knowledge Store page, chat experience.
- Requirements presentation decks (full version and short version for senior leadership).
- Living design specification.
- Engineering requirements document: 13 user stories, full acceptance criteria, release scope split.
Outcomes
Aligned, scoped, and ready for sprint planning
- Experience requirements aligned with senior leadership (two senior directors, principal PM).
- Release scope defined and agreed: August 2026 like-for-like replacement, November 2026 new capability.
- Engineering requirements drafted and structured, ready for sprint planning.
- Requirements page updated as the live reference for both teams.
- Cross-functional design working relationship established with the AI platform team.
No user metrics are available yet — the product is not live. When it ships, the metrics I expect to track are: time to first useful response, rate of context badge dismissal (indicating confusion about automatic context), and frequency of Knowledge Store connector toggle-off (indicating trust issues with institutional knowledge sources). These are the signals that will tell us whether the design decisions were right.
What I would do differently
Where I would push harder next time
Get user access earlier. Working without any direct practitioner input for this long is a risk. The design principles are well-reasoned and leadership-validated, but assumptions about how lawyers and bankers actually behave with AI tools have not been tested with real users. I would have pushed harder to get even three or four conversations with practitioners in the first month.
Define the design ownership boundary on day one. The unclear boundary between my work and the AI platform team's design ownership created friction I had to manage throughout. I should have requested a formal agreed scope from both design leads at the start, not let it remain implicit.
Push for a named PM replacement sooner. I operated without PM coverage for months by staying rigorous about what required PM versus design input. But some decisions would have moved faster with active PM ownership. The gap should have been escalated formally earlier.
Reflection
Designing for a capability still being built
This project sits in a category of design work I find genuinely interesting: designing for a capability that is still being built, where some of your requirements depend on technical answers you do not yet have.
The discipline it required was not just UX process. It was knowing which decisions to make now, which to hold open without letting ambiguity stall progress, and which to escalate rather than resolve through design choices alone. It required writing documentation that would survive my absence, hold up to scrutiny from engineering and product, and still be useful to a new team member who joined mid-project. The design is not finished. The product is not live. I will update this case study when it ships.